分布式系統架構和(hé / huò)設計

使用本福德定律甄别數據造假(Benford’s Law)
數據造假的(de)甄别在(zài)數據分析領域是(shì)一(yī / yì /yí)個(gè)熱門的(de)話題,也(yě)是(shì)對數據分析師的(de)一(yī / yì /yí)項挑戰。分析數據造假的(de)方法有很多種。我們在(zài)前面的(de)系列文章中曾經介紹過兩種檢驗作弊流量的(de)方法。一(yī / yì /yí)種是(shì)根據曆史經驗及分布情況的(de)多維度交叉檢驗,另一(yī / yì /yí)種是(shì)使用随機森林模型根據已知作弊流量的(de)特征對新流量進行分類及預測。

本篇文章介紹一(yī / yì /yí)種神奇的(de)數據檢驗方法,本福德定律(Benford's Law)。本福德定律是(shì)一(yī / yì /yí)種用途廣泛的(de)數據檢驗方法,在(zài)安然公司破産和(hé / huò)伊朗大(dà)選選票甄别中都曾被使用到(dào)。本福德定律通過自然生成的(de)數字中1到(dào)9的(de)使用頻率對數據進行檢驗。如果你的(de)數據具備一(yī / yì /yí)定規模,沒有人(rén)工設定的(de)最大(dà)值和(hé / huò)最小值,并且數據本身受人(rén)爲(wéi / wèi)因素影響較小。那麽就(jiù)可以(yǐ)使用本福德定律對數據進行檢驗,甄别數據是(shì)否經過人(rén)爲(wéi / wèi)修飾。
本福德定律及公式
本福德定律中自然生成的(de)數字首位爲(wéi / wèi)1的(de)概率爲(wéi / wèi)30.10%,2的(de)概率爲(wéi / wèi)17.61%,依次遞減,首位爲(wéi / wèi)9的(de)概率僅爲(wéi / wèi)4.58%。依據這(zhè)一(yī / yì /yí)期望概率值我們可以(yǐ)對數據進行檢驗。以(yǐ)下是(shì)本福德定律的(de)計算公式。通過這(zhè)一(yī / yì /yí)公式可以(yǐ)計算出(chū)1-9中每個(gè)數字出(chū)現數據首位的(de)概率。
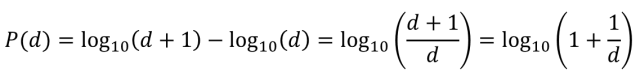
舉例來(lái)說(shuō),對于(yú)數字9下面的(de)公式可以(yǐ)計算出(chū)一(yī / yì /yí)組自然生成的(de)數字中9出(chū)現在(zài)數字首位的(de)概率是(shì)多少。
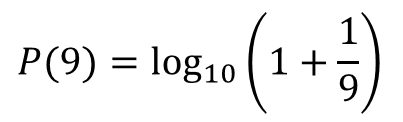
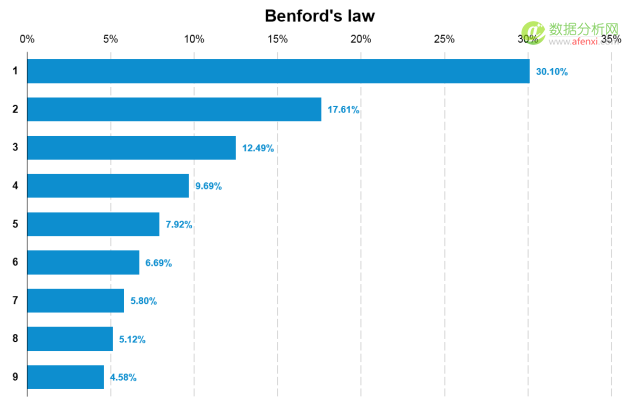
我們使用本福德定律公式逐一(yī / yì /yí)計算了(le/liǎo)數字1-9出(chū)現在(zài)首位的(de)概率。以(yǐ)下是(shì)每個(gè)數字出(chū)現的(de)概率值。後面會根據這(zhè)一(yī / yì /yí)期望的(de)概率值對數據是(shì)否進行過人(rén)工修改進行甄别。
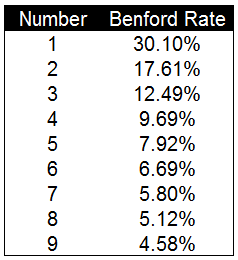
通過圖表可以(yǐ)更較直觀的(de)看到(dào)本福德定律中每個(gè)數字出(chū)現的(de)頻率以(yǐ)及不(bù)同數字間的(de)差異。與我們想象的(de)不(bù)同,數字出(chū)現的(de)頻率并不(bù)是(shì)均勻分布的(de)。1出(chū)現的(de)次數爲(wéi / wèi)30.10%而(ér)9出(chū)現的(de)次數僅爲(wéi / wèi)4.58%。
 下面我們将使用本福德定律對工作中常見的(de)數據進行檢驗,甄别數據是(shì)否經過人(rén)爲(wéi / wèi)修飾。
下面我們将使用本福德定律對工作中常見的(de)數據進行檢驗,甄别數據是(shì)否經過人(rén)爲(wéi / wèi)修飾。
廣告展現量數據檢驗
首先檢驗一(yī / yì /yí)組廣告曝光數據。下面是(shì)某廣告一(yī / yì /yí)段時(shí)間的(de)曝光量數據。我們将每條展現量數據的(de)第一(yī / yì /yí)個(gè)數字提取出(chū)來(lái),通過本福德定律對這(zhè)組數據進行檢驗。

第一(yī / yì /yí)步計算展現量數據中數字1-9出(chū)現的(de)次數。第二步計算所有展現量數據的(de)條目,展現量數據爲(wéi / wèi)474條。第三步計算數字1-9出(chū)現次數的(de)頻率。第四步使用本福德定律計算出(chū)數字1-9出(chū)現頻率的(de)期望值。
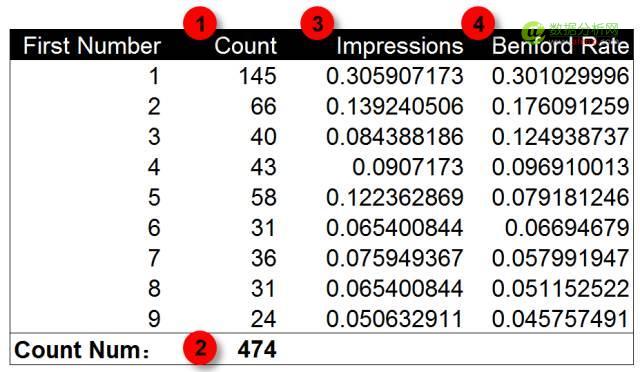
将曝光量數據和(hé / huò)本福德定律的(de)期望值繪制到(dào)圖表中進行對比,可以(yǐ)發現曝光量數據首位數字出(chū)現的(de)頻率與本福德定律整體上(shàng)基本一(yī / yì /yí)緻。在(zài)數字2,3和(hé / huò)5上(shàng)略有差異。這(zhè)個(gè)柱狀圖能說(shuō)明什麽?表明數據符合本福德定律?三個(gè)數據點上(shàng)的(de)差異又說(shuō)明什麽?數據中存在(zài)人(rén)爲(wéi / wèi)修飾嗎?

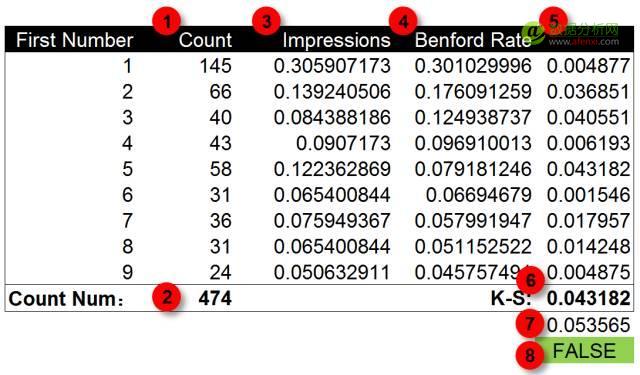
單從實際概覽值和(hé / huò)圖表上(shàng)我們無法辨别數據是(shì)否經過人(rén)爲(wéi / wèi)修飾。要(yào / yāo)準确的(de)判斷數據是(shì)否爲(wéi / wèi)自然生成還需要(yào / yāo)計算兩個(gè)指标,分别爲(wéi / wèi)KS值和(hé / huò)截止值。然後對兩個(gè)指标進行對比。如果KS值低于(yú)截止值,那麽可以(yǐ)判定數據爲(wéi / wèi)自然生成,沒有經過人(rén)工修飾。否則就(jiù)可能有造假的(de)風險。
KS值是(shì)數據的(de)實際概率值與期望概率值差異的(de)最大(dà)值,截止值是(shì)1.36除以(yǐ)數據條目數的(de)平方根。我們對前面的(de)數據表計算KS值和(hé / huò)截止值。第五步,計算實際概率值與期望概率值的(de)差異。這(zhè)裏我們取差異的(de)絕對值以(yǐ)避免負數的(de)産生。第六步,計算K-S值,經過計算K-S值爲(wéi / wèi)0.043,也(yě)就(jiù)是(shì)數字5出(chū)現頻率的(de)差異。第七步,計算截止值,這(zhè)裏的(de)曝光數據共有474條,因此截止值爲(wéi / wèi)0.053。第八步,對比K-S值與截止值,K-S值小于(yú)截止值。因此數據屬于(yú)自然生成。沒有經過人(rén)爲(wéi / wèi)修飾。
廣告點擊量數據檢驗
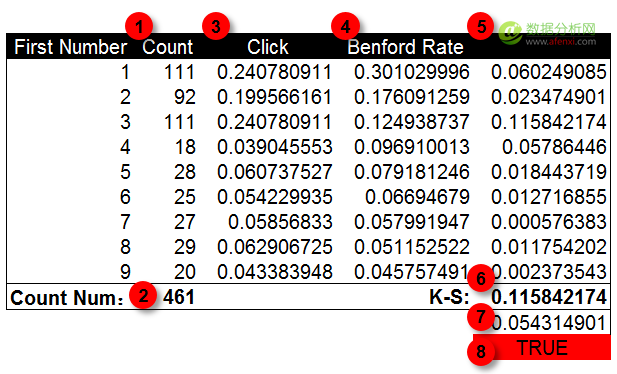
按照前面的(de)方法,我們對同一(yī / yì /yí)組廣告的(de)點擊量數據進行檢驗。在(zài)下面的(de)柱狀圖中,藍色爲(wéi / wèi)本福德定律的(de)期望概率值,綠色爲(wéi / wèi)廣告點擊量的(de)首位數字分布情況。可以(yǐ)發現在(zài)數字1,3和(hé / huò)4上(shàng)實際值與期望值之(zhī)間存在(zài)較大(dà)的(de)差異。尤其是(shì)在(zài)數字3上(shàng)。但僅根據這(zhè)幾個(gè)差異點我們還不(bù)能判斷數據是(shì)否經過人(rén)工修飾。
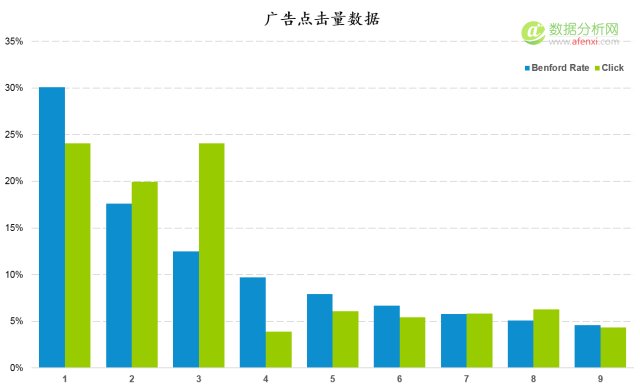
進一(yī / yì /yí)步計算K-S值和(hé / huò)截止值并進行對比。K-S值爲(wéi / wèi)數據點間的(de)最大(dà)差異值,這(zhè)裏是(shì)0.115。截止值經過計算爲(wéi / wèi)0.054。K-S值明顯大(dà)于(yú)截止值。因此可以(yǐ)判斷點擊量數據是(shì)經過人(rén)工修飾的(de)可能,需要(yào / yāo)進一(yī / yì /yí)步進行檢驗。
貸款金額數據檢驗
除了(le/liǎo)廣告數據以(yǐ)外,本福德定律還可以(yǐ)在(zài)很多場景下對數據進行檢驗。如貸款金額的(de)數據。下面是(shì)一(yī / yì /yí)組貸款金額首位數字分布與本福德定律逾期分布的(de)對比圖。兩者的(de)趨勢一(yī / yì /yí)緻,差異也(yě)較小。
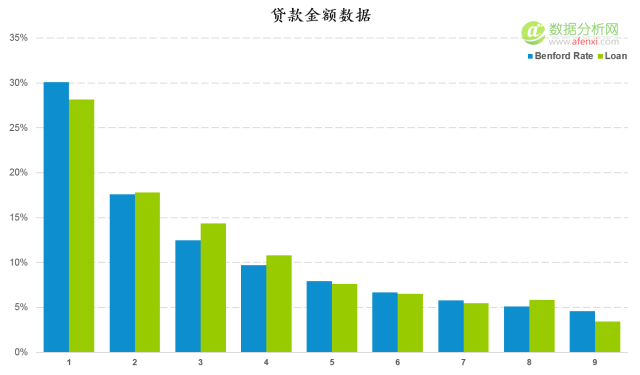
通過計算K-S值和(hé / huò)截止值并進行對比,K-S值0.019小于(yú)截止值0.022。說(shuō)明貸款金額數據爲(wéi / wèi)自然生成,不(bù)存在(zài)人(rén)工修飾。

Excel随機數檢驗
最後,我們人(rén)工生成一(yī / yì /yí)組”假數據”,看看本福德定律的(de)檢驗結果。這(zhè)裏使用Excel的(de)随機數函數生成100個(gè)随機數。并與本福德定律的(de)期望分布進行對比。很明顯,Excel生成的(de)随機數在(zài)首位數字上(shàng)爲(wéi / wèi)均勻分布。與本福德定律的(de)期望分布相差甚遠。
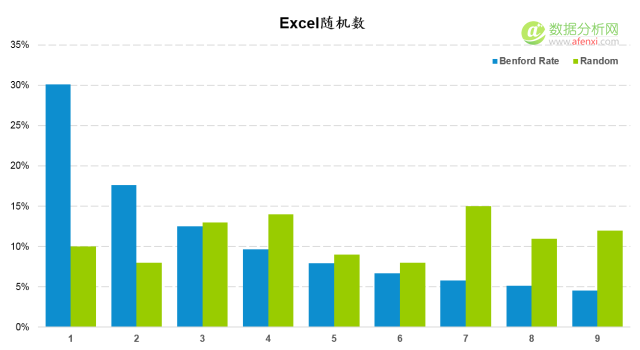
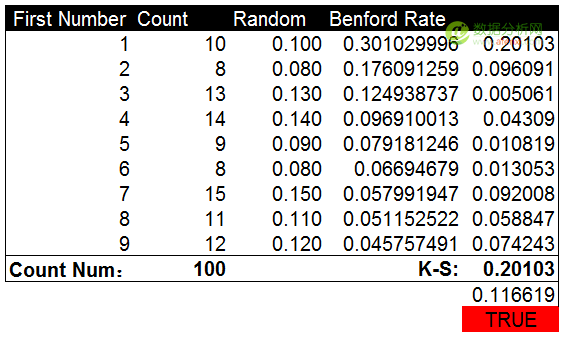
計算并對比K-S值和(hé / huò)截止值也(yě)再次證明了(le/liǎo)均勻分布的(de)數據爲(wéi / wèi)人(rén)工生成。K-S值0.201大(dà)于(yú)截止值0.116。
本福德定律加強版
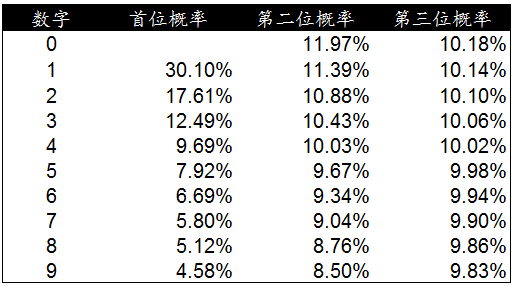
本福德定律除了(le/liǎo)計算首位數字出(chū)現的(de)概率,還有個(gè)加強版,可以(yǐ)計算第二位數字甚至第三位數字出(chū)現的(de)概率,并通過這(zhè)些這(zhè)些期望值對數據進行更加深入和(hé / huò)嚴格的(de)檢驗。下面是(shì)計算第二位數字出(chū)現概率的(de)公式。d1表示第一(yī / yì /yí)位出(chū)現的(de)數字,d2表示第二位出(chū)現的(de)數字。
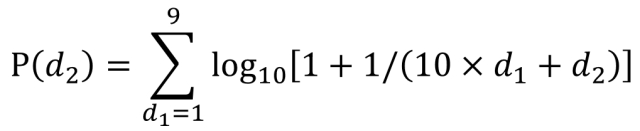
如果我們要(yào / yāo)計算第二位數字爲(wéi / wèi)6的(de)期望值,将數字6代入公式中,如下面截圖所示。分别計算1-9每個(gè)數字與第二位數字6進行組合時(shí)的(de)概率,再進行加總就(jiù)是(shì)數字6作爲(wéi / wèi)第二位出(chū)現數字的(de)期望概率值。
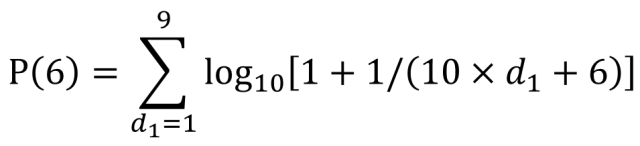
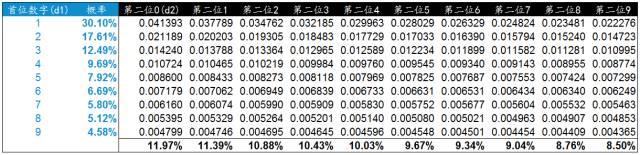
在(zài)Excel中實際計算下,藍色部分爲(wéi / wèi)首位數字和(hé / huò)出(chū)現的(de)概率。後面依次是(shì)第二位數字從0-9依次與首位數字組合出(chū)現的(de)概率值。我們按列進行彙總就(jiù)是(shì)每個(gè)第二位數字出(chū)現的(de)概率。
再進一(yī / yì /yí)步還可以(yǐ)計算第三位數字出(chū)現的(de)概率。方法與計算第二位數字出(chū)現的(de)方法類似,隻是(shì)更爲(wéi / wèi)負責一(yī / yì /yí)些。下面是(shì)計算公式。将0-9的(de)10個(gè)數字分别與前兩位的(de)各種數字組合在(zài)一(yī / yì /yí)起計算,然後把每種情況單一(yī / yì /yí)數字出(chū)現的(de)概率進行彙總,就(jiù)是(shì)這(zhè)個(gè)數字出(chū)現在(zài)第三位的(de)期望值了(le/liǎo)。
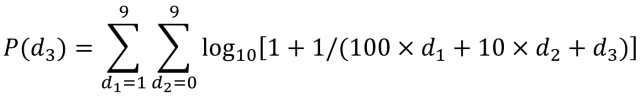
以(yǐ)第三位數字是(shì)0爲(wéi / wèi)例,藍色列表示第一(yī / yì /yí)位數字的(de)值,由于(yú)第一(yī / yì /yí)位不(bù)能爲(wéi / wèi)0,所以(yǐ)數字範圍爲(wéi / wèi)1-9。第一(yī / yì /yí)行黑色背景爲(wéi / wèi)第二位數字的(de)值,從0-9。計算各種組合情況下第三位數字爲(wéi / wèi)0的(de)概率,并進行彙總。最終0.1018就(jiù)是(shì)0作爲(wéi / wèi)第三位數字出(chū)現的(de)概率值。

我們按照同樣的(de)方法計算了(le/liǎo)0-9在(zài)第三位出(chū)現的(de)概率,并與前面計算的(de)首位和(hé / huò)第二位數字出(chū)現概率進行彙總生成了(le/liǎo)下面的(de)數據檢驗表。通過這(zhè)個(gè)概率分布表可以(yǐ)更加深入的(de)對數據的(de)真實性進行檢驗。