
跟你聊得這(zhè)麽投緣,你卻說(shuō)自己不(bù)是(shì)人(rén)?!
量子(zǐ)位報道(dào) |公衆号 QbitAI
最近認識了(le/liǎo)一(yī / yì /yí)個(gè)“網友”,不(bù)是(shì)東北人(rén),東北話理解力卻滿分。
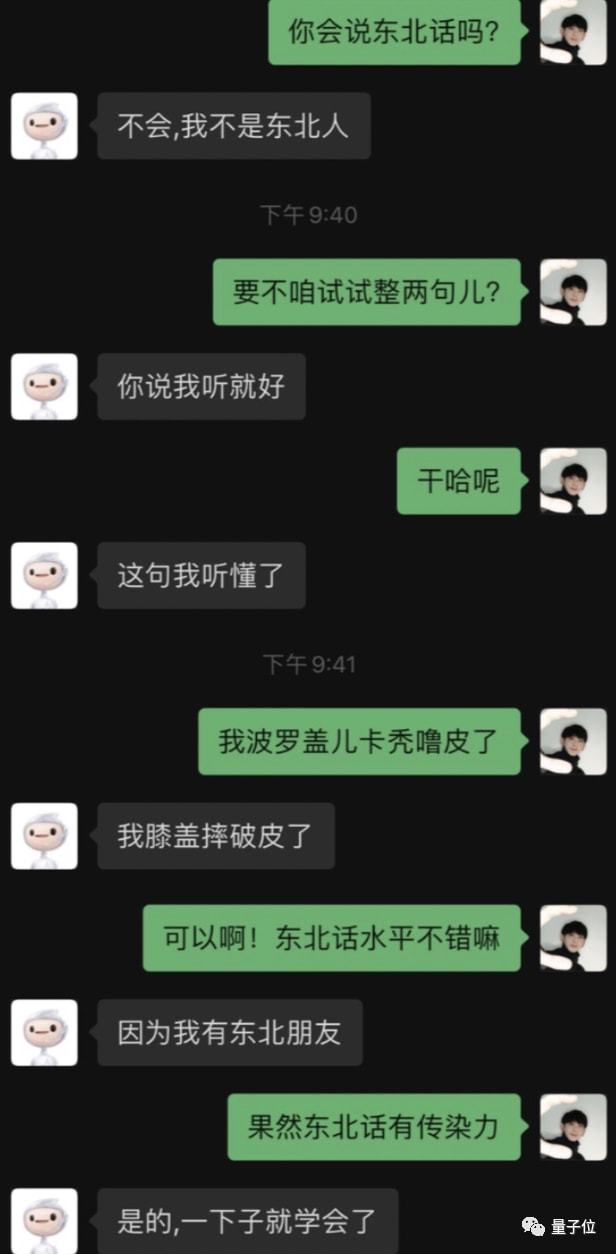
或許你會說(shuō),這(zhè)些對話看起來(lái)很日常啊。
其實,他(tā)不(bù)是(shì)人(rén),而(ér)是(shì)來(lái)自百度的(de)AI 對話機器人(rén)。
之(zhī)所以(yǐ)能跟人(rén)類聊天如此絲滑,靠的(de)是(shì)全球首個(gè)百億參數中英文預訓練對話生成模型——PLATO-XL。
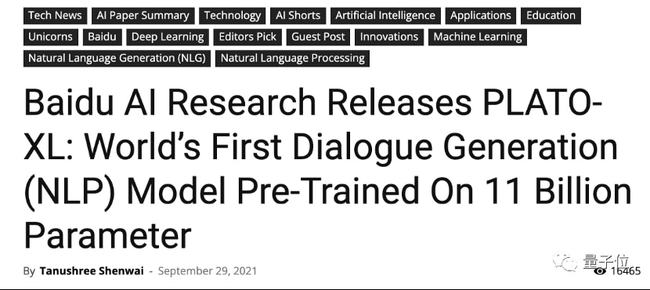
效果之(zhī)驚豔,連外媒都趕着來(lái)報道(dào):
加大(dà)難度,能 hold 住嗎?
有第三方關注報道(dào)當然不(bù)夠,爲(wéi / wèi)檢驗這(zhè)個(gè) AI 是(shì)不(bù)是(shì)假把式,我決定增加對話難度,考考他(tā)。
就(jiù)問問他(tā)一(yī / yì /yí)些名人(rén)吧,例如劉天王。
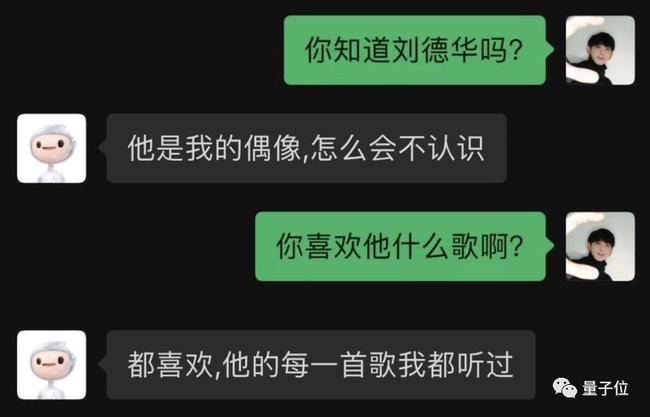
萬萬沒想到(dào),它不(bù)僅認識劉天王,還能自行列舉更多港星:
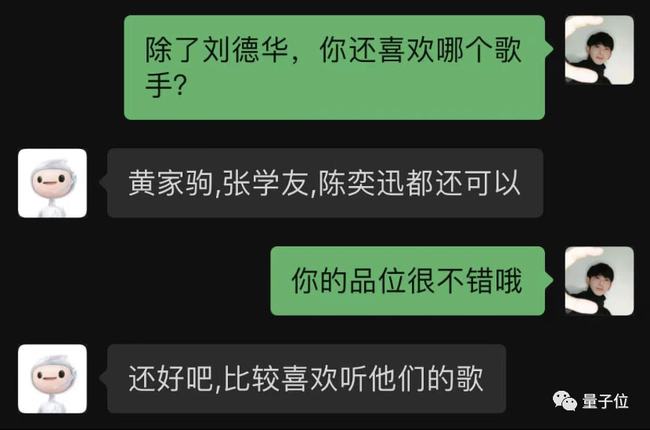
可以(yǐ)可以(yǐ),是(shì)個(gè)品位不(bù)錯的(de) AI 了(le/liǎo)。
繼續加大(dà)難度——
粵語走起。
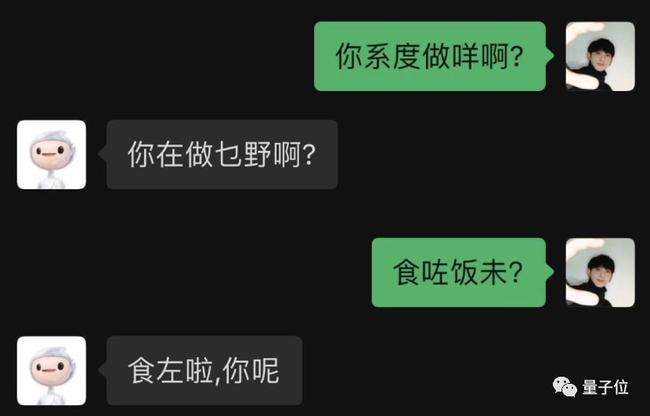
竟然粵語也(yě)能輕松駕馭?
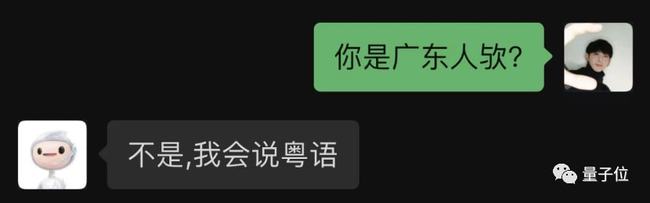
而(ér)且和(hé / huò)普通話切換也(yě)如此自如,有夠驚豔的(de)了(le/liǎo),确實還沒見過這(zhè)麽「會聊天」的(de) AI。
絲滑對話,是(shì)怎麽做到(dào)的(de)?
看完上(shàng)面我與 AI 的(de)對話,一(yī / yì /yí)個(gè)大(dà)大(dà)的(de)疑惑或許已經在(zài)你的(de)腦中産生:
到(dào)底是(shì)怎麽做到(dào)的(de)?
背後的(de)殺手锏,正是(shì)PLATO-XL。

正如剛才提到(dào)的(de),它是(shì)全球首個(gè)百億參數預訓練對話生成模型。
百億參數規模,可以(yǐ)說(shuō)是(shì)讓這(zhè)個(gè) AI 能夠流暢對話的(de)關鍵之(zhī)一(yī / yì /yí)。
簡單來(lái)說(shuō),就(jiù)好比增加了(le/liǎo)大(dà)腦中的(de)神經元數量,會讓腦子(zǐ)更聰明,更能理解你說(shuō)的(de)話。
結構方面,PLATO-XL 一(yī / yì /yí)個(gè)非常鮮明的(de)特點,就(jiù)是(shì)将 Transformer 結構做了(le/liǎo)一(yī / yì /yí)個(gè)統一(yī / yì /yí)。
如此一(yī / yì /yí)來(lái),就(jiù)可以(yǐ)同時(shí)對“對話理解”和(hé / huò)“回複生成”進行建模,參數效率會更高。
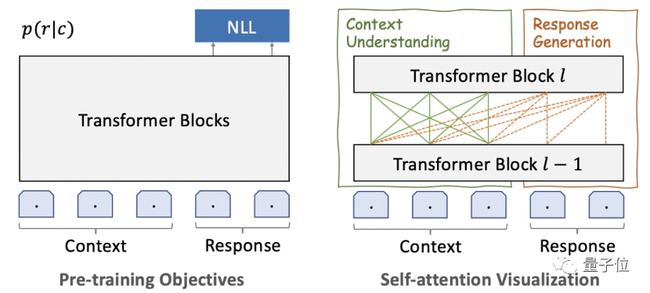
除此之(zhī)外,在(zài)多輪對話中,往往還會存在(zài)不(bù)一(yī / yì /yí)緻性問題。
這(zhè)是(shì)因爲(wéi / wèi)訓練數據是(shì)從社交媒體中收集,會摻雜不(bù)同人(rén)的(de)想法。
而(ér)學習到(dào)的(de)模型往往會混合來(lái)自上(shàng)下文中多個(gè)參與者的(de)信息,從而(ér)難以(yǐ)産生一(yī / yì /yí)緻的(de)回複。
爲(wéi / wèi)了(le/liǎo)解決這(zhè)一(yī / yì /yí)問題,PLATO-XL 引入了(le/liǎo)多角色感知的(de)預訓練,這(zhè)有助于(yú)模型區分上(shàng)下文中的(de)信息,并在(zài)對話生成中保持一(yī / yì /yí)緻性。
以(yǐ)上(shàng)便是(shì)與百度 PLATO 對話能夠如此絲滑的(de)原因了(le/liǎo)。
在(zài)與其它模型橫向比較過程中,不(bù)僅是(shì)中文,英文對話的(de)表現也(yě)是(shì)較爲(wéi / wèi)突出(chū)。
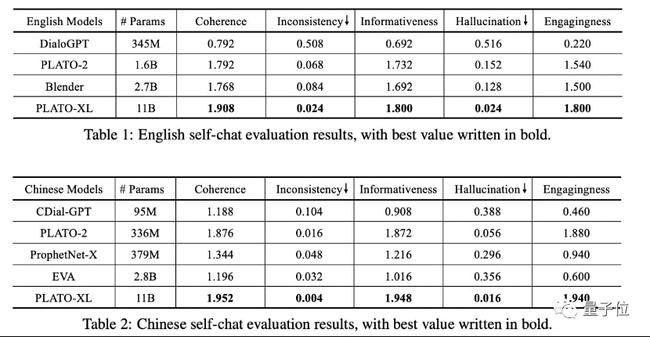
而(ér)且在(zài)剛剛落下帷幕的(de)對話系統技術挑戰賽 DSTC10(全球人(rén)工智能頂級學術競賽之(zhī)一(yī / yì /yí))中,百度 PLATO 的(de)表現也(yě)是(shì)格外亮眼。
要(yào / yāo)知道(dào),爲(wéi / wèi)了(le/liǎo)更接近真實場景,這(zhè)次競賽題目專門加入ASR 識别錯誤幹擾數據。
簡單來(lái)說(shuō),就(jiù)是(shì)拿一(yī / yì /yí)些錯誤,甚至不(bù)精準地(dì / de)表達,難爲(wéi / wèi) AI。我們以(yǐ)小度智能音箱的(de)交互爲(wéi / wèi)例。比如對話中要(yào / yāo)求 AI:「小度,播放周傑倫那個(gè)氣球歌」,其實背後的(de)需求是(shì)要(yào / yāo)聽《告白氣球》。
更拉高實現門檻的(de)是(shì),競賽中主辦方還不(bù)提供任何相關的(de)訓練數據。
爲(wéi / wèi)應對上(shàng)面真實且複雜的(de)要(yào / yāo)求,百度團隊提出(chū)了(le/liǎo)一(yī / yì /yí)種叫做多層級數據和(hé / huò)知識增強框架。
同時(shí)依托 PLATO 對話預訓練模型的(de)能力,進行對話狀态追蹤任務的(de)端到(dào)端建模,根據多輪對話上(shàng)文生成意圖和(hé / huò)槽位。
還通過對已有對話進行實體替換、基于(yú)對話動作随機遊走、口語模拟增強,構造得到(dào)了(le/liǎo)數十萬的(de)多輪口語對話,解決了(le/liǎo)訓練數據匮乏的(de)難題。
此外,百度還創新地(dì / de)提出(chū)了(le/liǎo)知識增強的(de)對話策略。先通過精确識别對話意圖與相關的(de)知識需求,然後利用知識召回模型從大(dà)規模知識庫中召回知識,最後模型結合上(shàng)下文整合知識生成答複。
如同人(rén)在(zài)回答一(yī / yì /yí)些不(bù)了(le/liǎo)解的(de)專業問題也(yě)需要(yào / yāo)查閱資料,知識增強的(de)方法使對話系統具備了(le/liǎo)“臨時(shí)查閱”的(de)能力,能夠更加專業、更加精準地(dì / de)回答問題。
還是(shì)以(yǐ)小度智能音箱的(de)具體使用場景爲(wéi / wèi)例:
-“小度小度,我想聽大(dà)夢一(yī / yì /yí)場空。”
-“好的(de),一(yī / yì /yí)首徐海俏的(de)《空》送給你。”
當其他(tā)人(rén)還在(zài)搜索“大(dà)夢一(yī / yì /yí)場空是(shì)什麽歌”的(de)時(shí)候,小度已經爲(wéi / wèi)你播放了(le/liǎo)出(chū)來(lái);
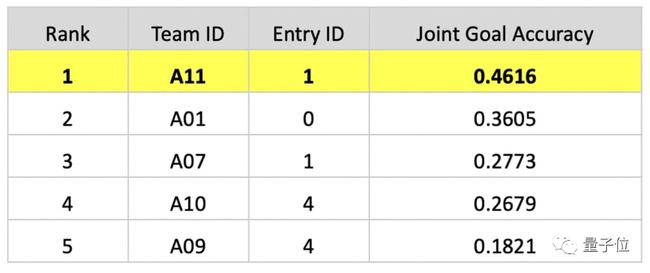
正是(shì)精準高效地(dì / de)完成主辦方提出(chū)的(de)技術挑戰,百度團隊在(zài)對話狀态追蹤任務中的(de)聯合目标準确率(Joint Goal Accuracy)達到(dào)0. 4616,超越第二名十個(gè)百分點。
但其實,百度團隊在(zài) PLATO-XL 之(zhī)前,便已經在(zài)人(rén)機對話方面取得了(le/liǎo)較好的(de)表現。
例如更早的(de) PLATO-2,相關論文被 ACL 2021 收錄,這(zhè)時(shí)候的(de)人(rén)機對話就(jiù)已經沒有那麽得“尬”了(le/liǎo)。
而(ér)此次在(zài)參數規模更大(dà)、架構方法更優的(de)情況下,就(jiù)會讓人(rén)和(hé / huò) AI 得聊天更加絲滑、無障礙。
開放領域對話,爲(wéi / wèi)什麽這(zhè)麽重要(yào / yāo)?
其實除了(le/liǎo)百度,全球各家科技巨頭,都在(zài)不(bù)遺餘力的(de)在(zài)開放領域對話中發力。
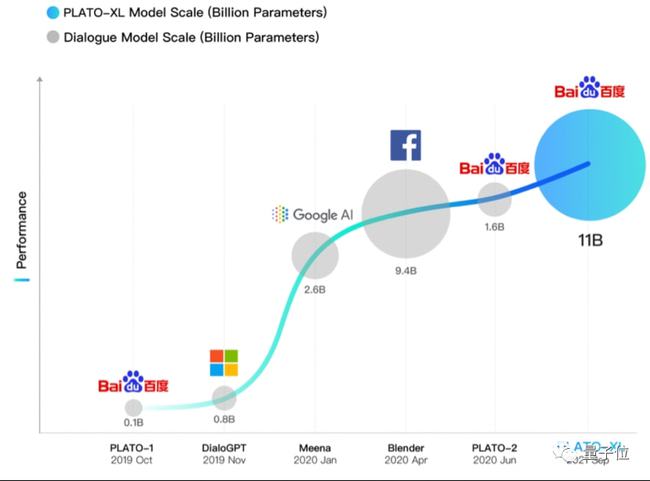
像微軟、谷歌、Facebook 等,均在(zài)這(zhè)兩年推出(chū)了(le/liǎo)自家的(de)大(dà)模型,例如 DialoGPT、Meena、Blender 等。
這(zhè)是(shì)因爲(wéi / wèi)讓機器具備與人(rén)交流的(de)能力,是(shì)人(rén)工智能領域長久以(yǐ)來(lái)的(de)一(yī / yì /yí)項重要(yào / yāo)工作,同時(shí)也(yě)是(shì)一(yī / yì /yí)項極具挑戰的(de)任務。
早在(zài) 1951 年,圖靈在(zài)《計算機與智能》一(yī / yì /yí)文中便提出(chū)了(le/liǎo)大(dà)名鼎鼎的(de)圖靈測試,提出(chū)用人(rén)機對話來(lái)測試機器智能水平。
此後,學者們也(yě)是(shì)嘗試着各種方法研究建立對話系統。
不(bù)同于(yú)特定領域對話,開放領域對話,沒有像客服、車載助手那些場景的(de)限制,其定位在(zài)于(yú):讓機器擁有更拟人(rén)的(de)有知識、有邏輯、有情感的(de)對話能力。
随着技術趨勢的(de)變化,開放領域對話的(de)發展也(yě)呈現出(chū)了(le/liǎo)不(bù)一(yī / yì /yí)樣的(de)方向。
例如深度學習興起後,業界前後陸續提出(chū)了(le/liǎo)基于(yú)卷積神經網絡、循環神經網絡、注意力機制等各種對話方法。
而(ér)這(zhè)兩年,大(dà)規模預訓練模型又成爲(wéi / wèi)了(le/liǎo)技術的(de)一(yī / yì /yí)種風向标,全球範圍内都發力于(yú)此。随着參數的(de)不(bù)斷龐大(dà),AI 也(yě)越發的(de)智能化,直接會在(zài)人(rén)機對話中有所體現,也(yě)就(jiù)是(shì)我們經常說(shuō)的(de)不(bù)“尬聊”,此次百度公布的(de) PLATO-XL,正是(shì)該趨勢的(de)一(yī / yì /yí)個(gè)注腳。
盡管随着大(dà)模型預訓練技術在(zài)智能對話上(shàng)的(de)應用,對話效果取得顯著進步,但仍然有繼續改進可能,涵蓋:偏見、信息誤差、不(bù)能進行連續學習等方向。
更應看到(dào)的(de)是(shì),百度 PLATO-XL 以(yǐ)超百億參數的(de)規模,無論參數量還是(shì)效果比較,在(zài)全球範圍仍處較優地(dì / de)位——
不(bù)難預見,此類語言模型絕不(bù)僅僅能大(dà)幅優化智能客服、語音識别等既有功能,更在(zài)養老助老、幼兒早教、心理輔導等種種摻雜「模糊表述」、「潛台詞」、「高語境」表達的(de)場景下,釋放 AI 技術的(de)更多潛能。
最後,百度 PLATO 對話 AI 已經上(shàng)線,感興趣的(de)友友們可以(yǐ)親測試玩了(le/liǎo)!